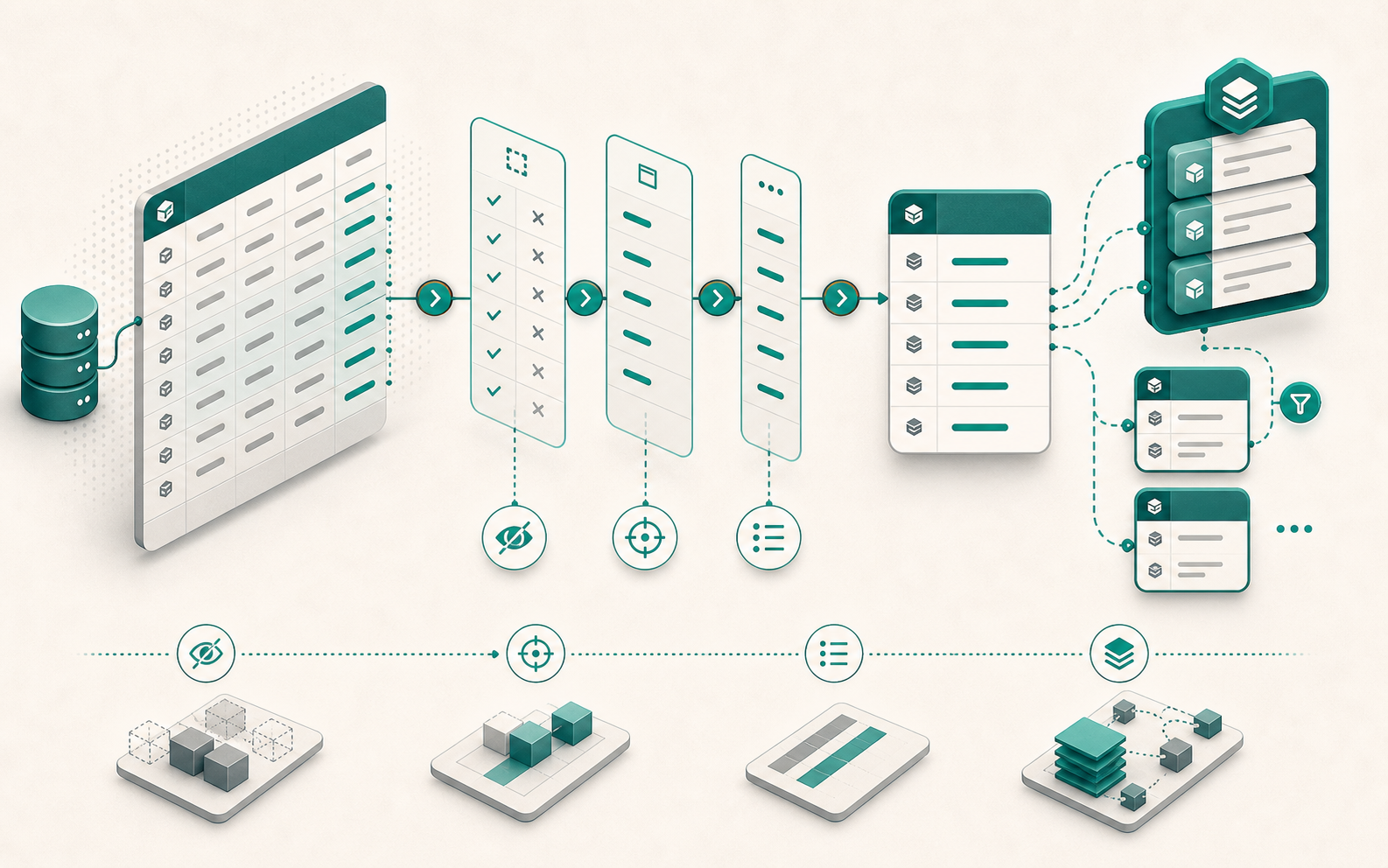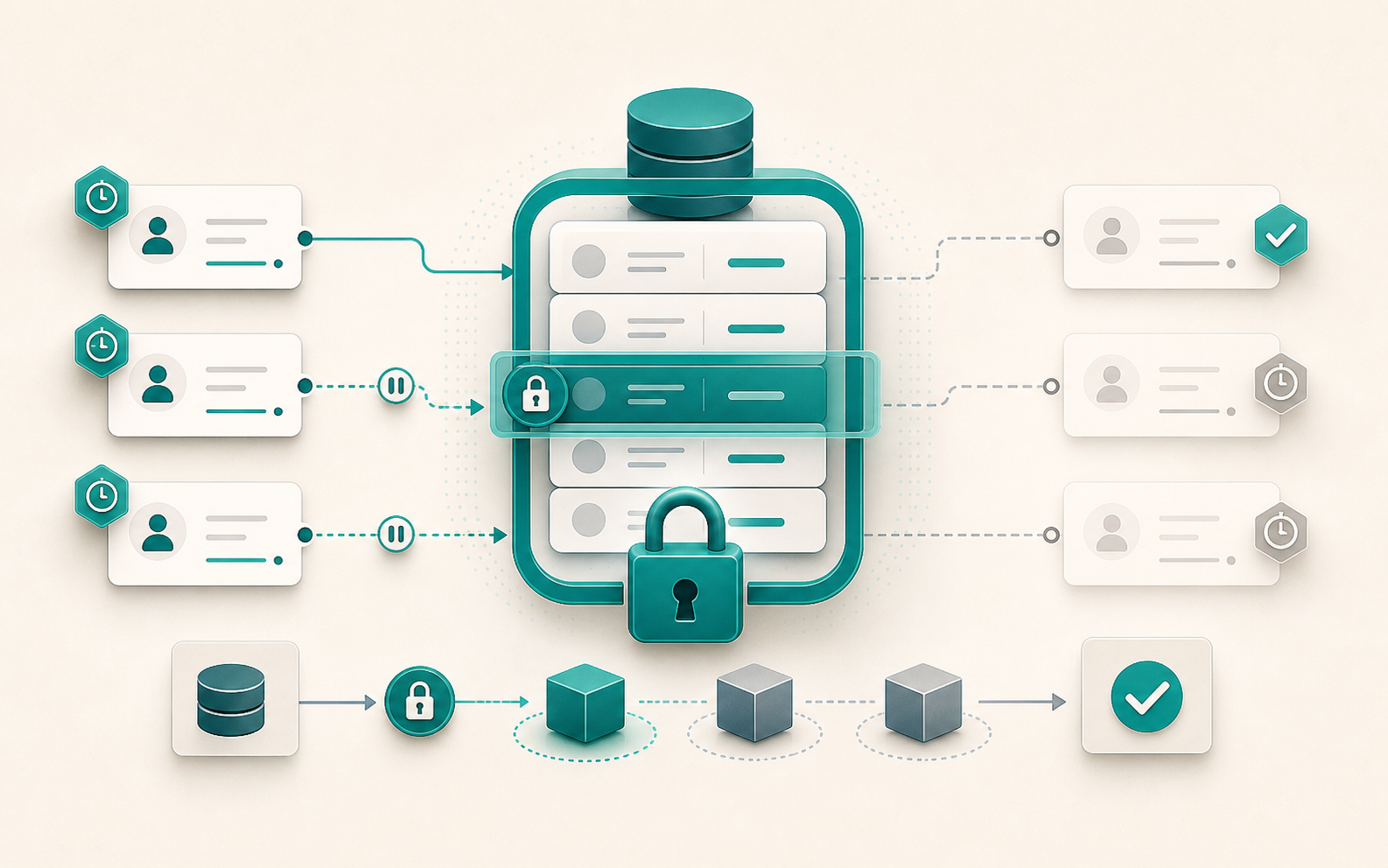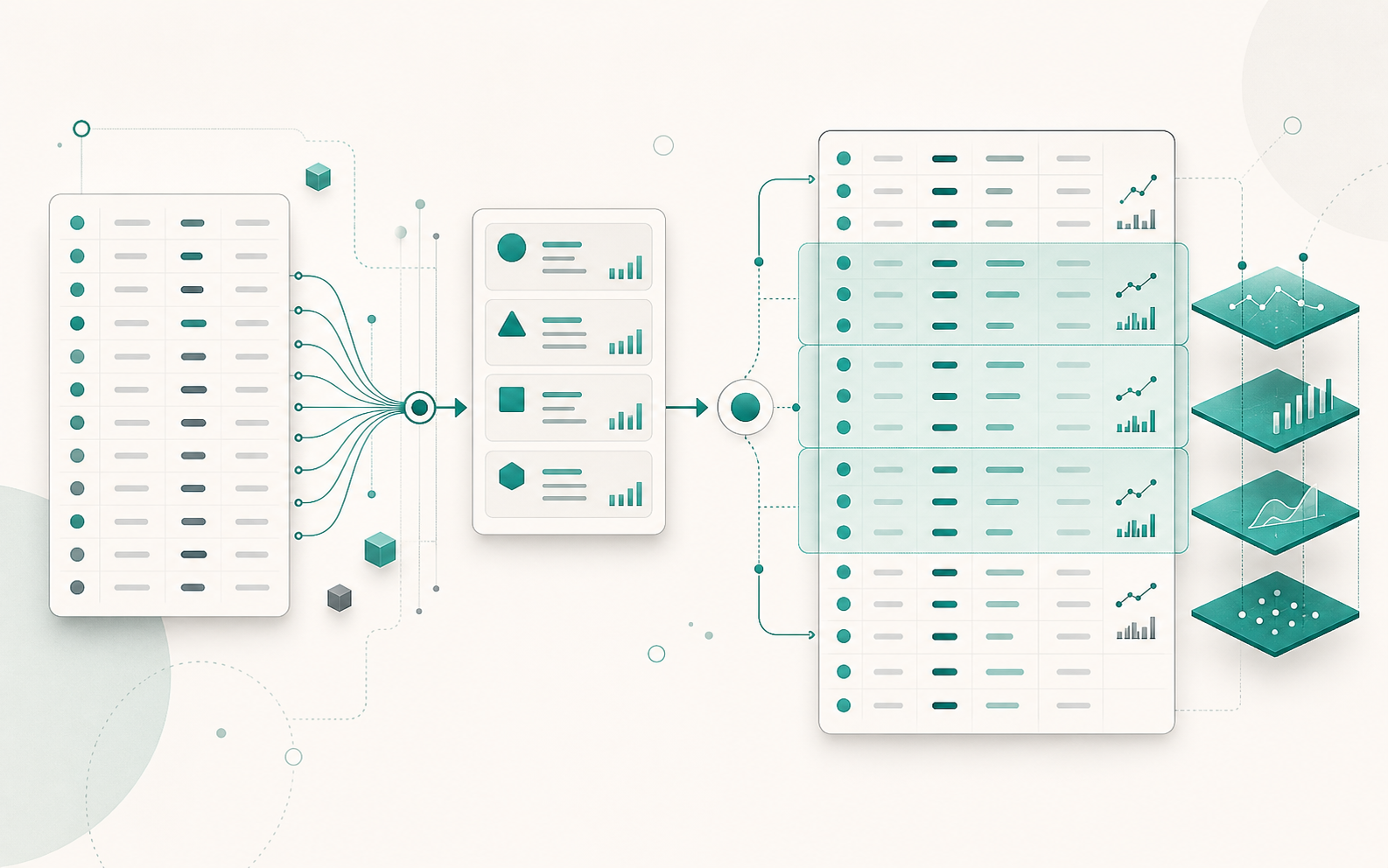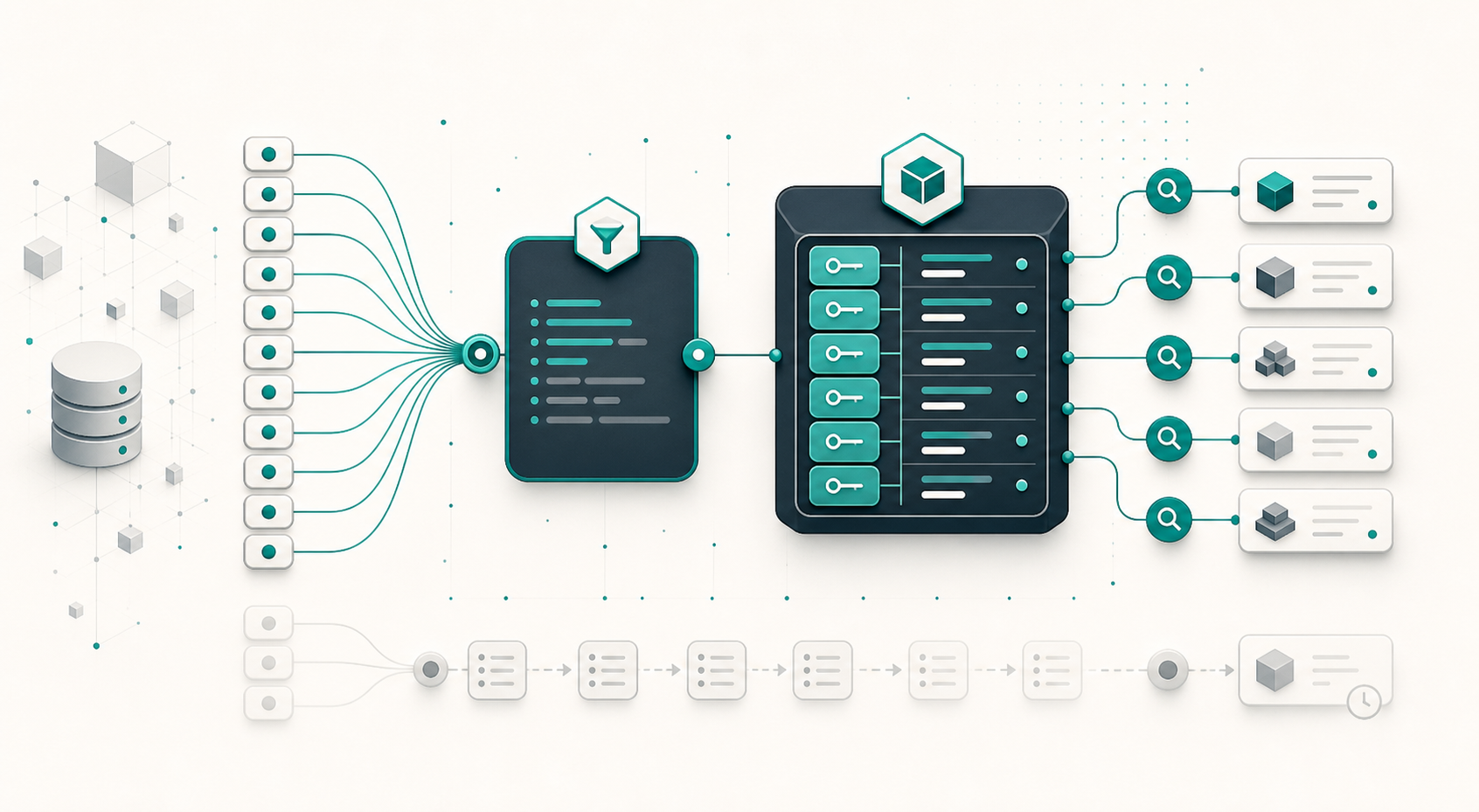
Django : save() ne valide pas — le cycle complet de validation
Appeler obj.save() après avoir défini des validators et un clean() sur le modèle laisse croire que la validation est garantie. Elle ne l’est pas. Django ne déclenche pas full_clean() lors d’un save(), et ce comportement est délibéré. Comprendre pourquoi change la façon d’architecturer la validation dans un projet. Ce que save() fait réellement Le cycle de vie d’un save() est plus court que ce qu’on imagine : Signal pre_save envoyé field.pre_save() appelé sur chaque champ (auto_now, auto_now_add, etc.) INSERT ou UPDATE SQL selon la présence d’un pk Signal post_save envoyé Aucune validation n’y figure. Ni vérification de blank, ni max_length, ni appel à clean(). C’est aussi vrai pour Model.objects.create() et Model.objects.bulk_create() : les trois méthodes persistent sans valider. (bulk_create() est traité en détail dans Django in_bulk() et bulk_create() si vous travaillez sur des insertions en masse.) ...