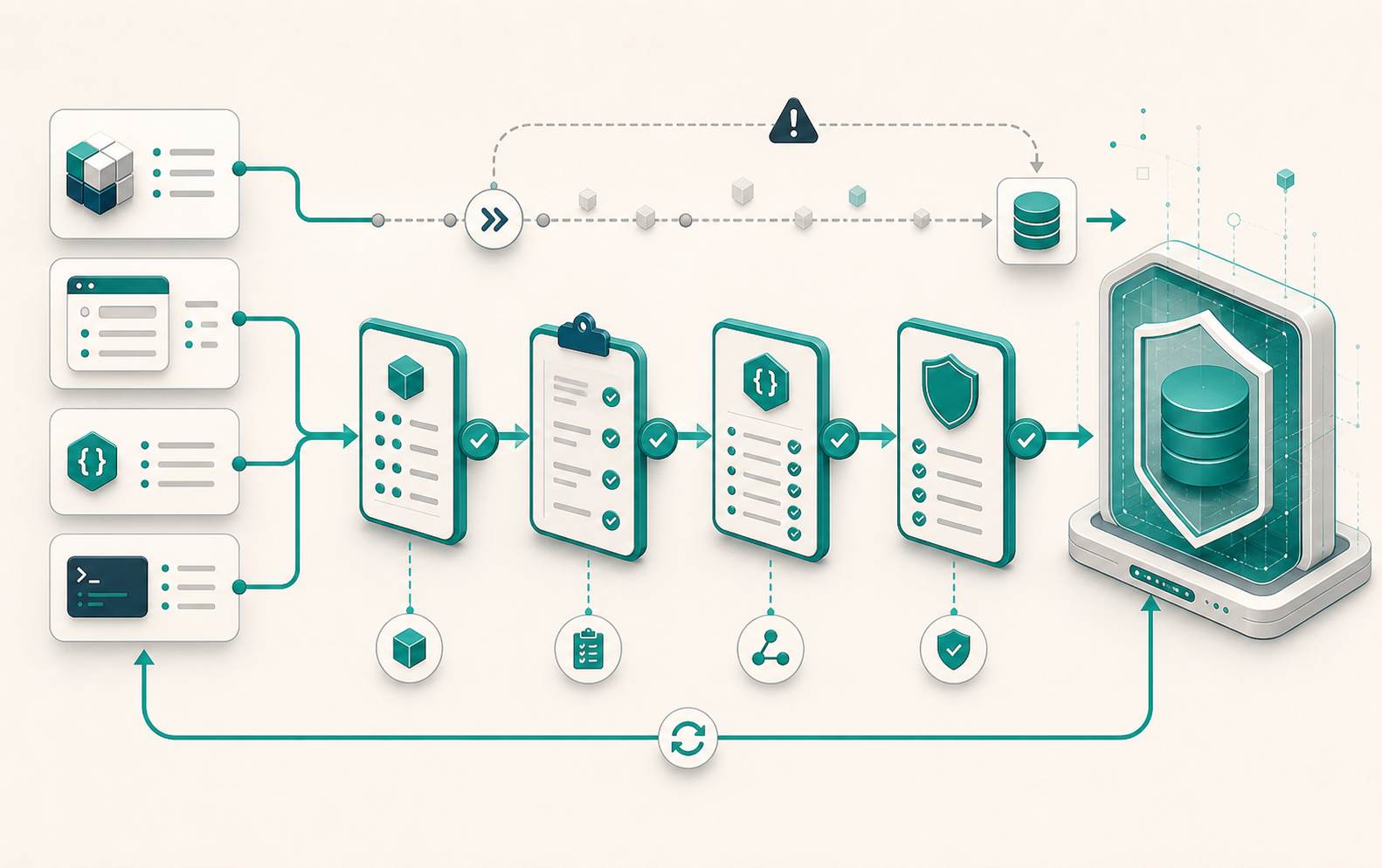
Django: save() no llama a full_clean() — ciclo de validación
Llamar a obj.save() después de definir validators y un método clean() en el modelo da la impresión de que la validación está garantizada. No lo está. Django no llama a full_clean() durante un save(), y este comportamiento es deliberado. Entender por qué cambia la forma de diseñar la validación en un proyecto. Lo que save() hace realmente El ciclo de vida de un save() es más corto de lo que parece: ...