Bonnes pratiques, tips et astuces autour de Python, Django, Django REST Framework, FastAPI et Flask. Approches TDD, SOLID et DDD pour des APIs backend solides.
Anthony.D
Développeur Python · Django · FastAPI · Flask · Freelance
Développeur Python · Django · FastAPI · Flask · Freelance
Bonnes pratiques, tips et astuces autour de Python, Django, Django REST Framework, FastAPI et Flask. Approches TDD, SOLID et DDD pour des APIs backend solides.

Le TDD attire deux réactions extrêmes. La première : “j’écris déjà des tests, donc je fais du TDD”. La seconde : “écrire les tests avant, c’est inverser l’effort sans gagner grand-chose”. Les deux passent à côté de ce que le TDD est vraiment. Ce n’est ni une question de couverture, ni une simple inversion d’ordre. C’est une discipline de design qui force à expliciter une intention avant d’écrire le code qui la satisfait. ...
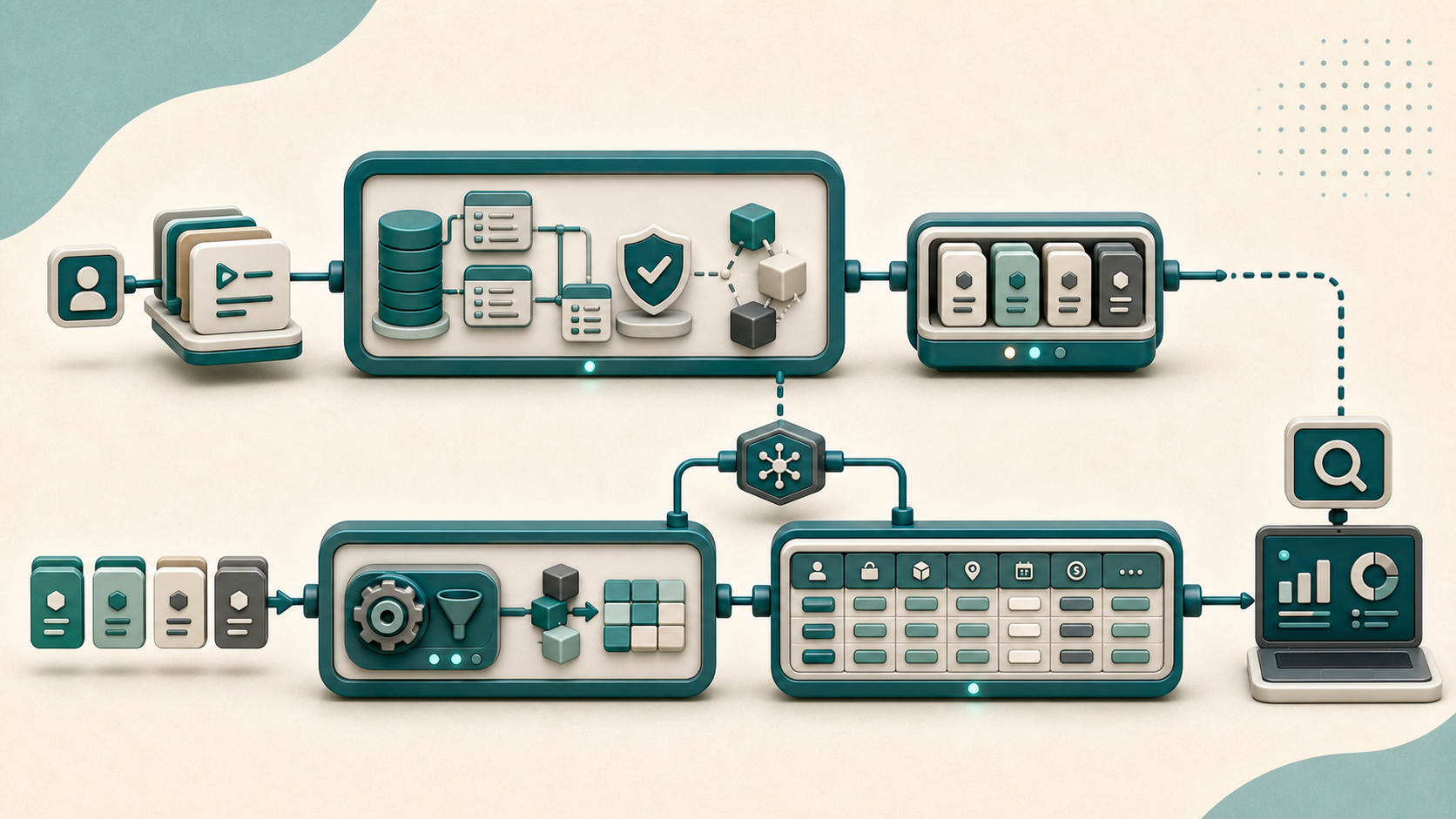
Les quatre articles précédents de la série ont posé les briques pour qu’un système distribué reste cohérent : Saga pour orchestrer des workflows, Outbox pour publier des événements fiables, Inbox pour les consommer sans doublon, Idempotency Keys pour protéger l’API. Il manque une question : que fait-on des événements une fois publiés ? La réponse la plus fréquente est : on les utilise pour construire des vues de lecture. C’est exactement ce que propose le pattern CQRS (Command Query Responsibility Segregation) : séparer le modèle d’écriture du modèle de lecture, quand les deux divergent suffisamment pour que les forcer dans une même structure coûte plus cher que les dédoubler. ...
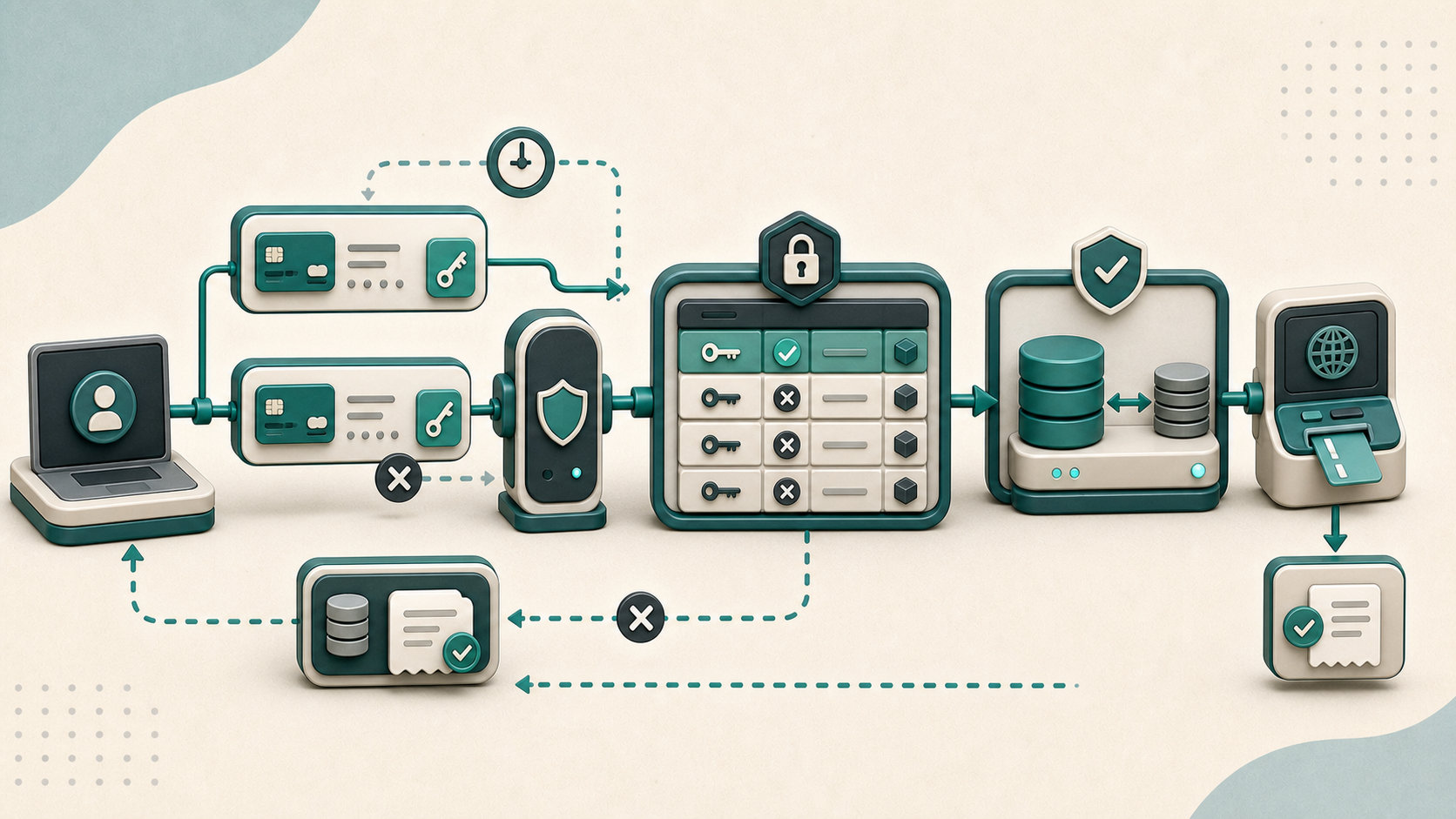
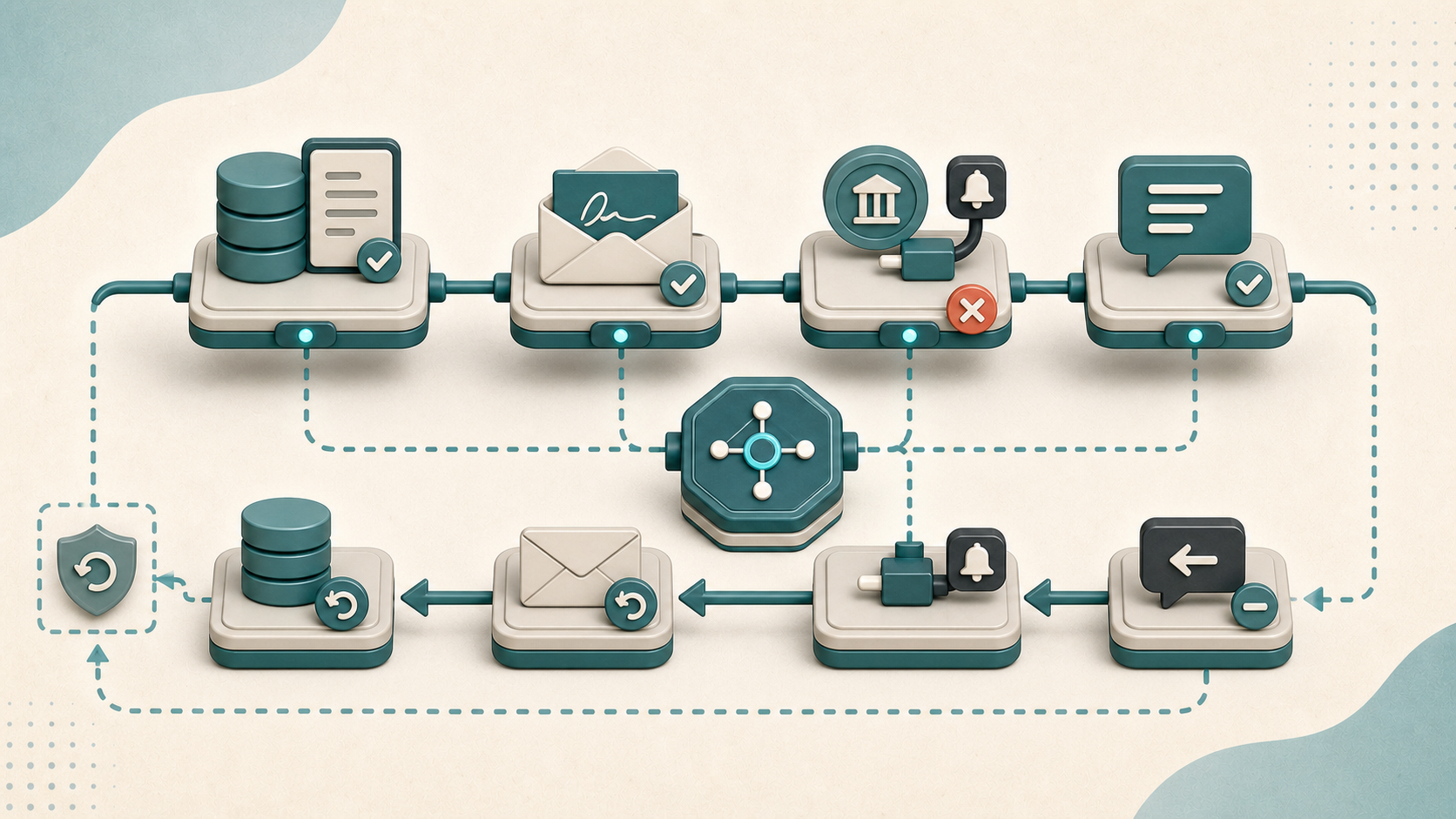
Les deux articles précédents ont traité l’idempotence côté événement : le pattern Outbox garantit qu’un message est publié au moins une fois, et le pattern Inbox garantit qu’il n’est consommé qu’une fois. Reste un troisième endroit où le même problème se pose, plus en amont : l’API HTTP elle-même. Quand un client lance un POST /api/payments et que sa connexion lâche avant de recevoir la réponse, il ne sait pas si le paiement a été créé ou non. S’il retry, il risque de payer deux fois. S’il ne retry pas, il risque de ne pas payer du tout. Le pattern Idempotency Key, popularisé par Stripe et adopté depuis par la plupart des APIs de paiement, résout ce dilemme en mettant le contrôle du retry dans les mains du client. ...
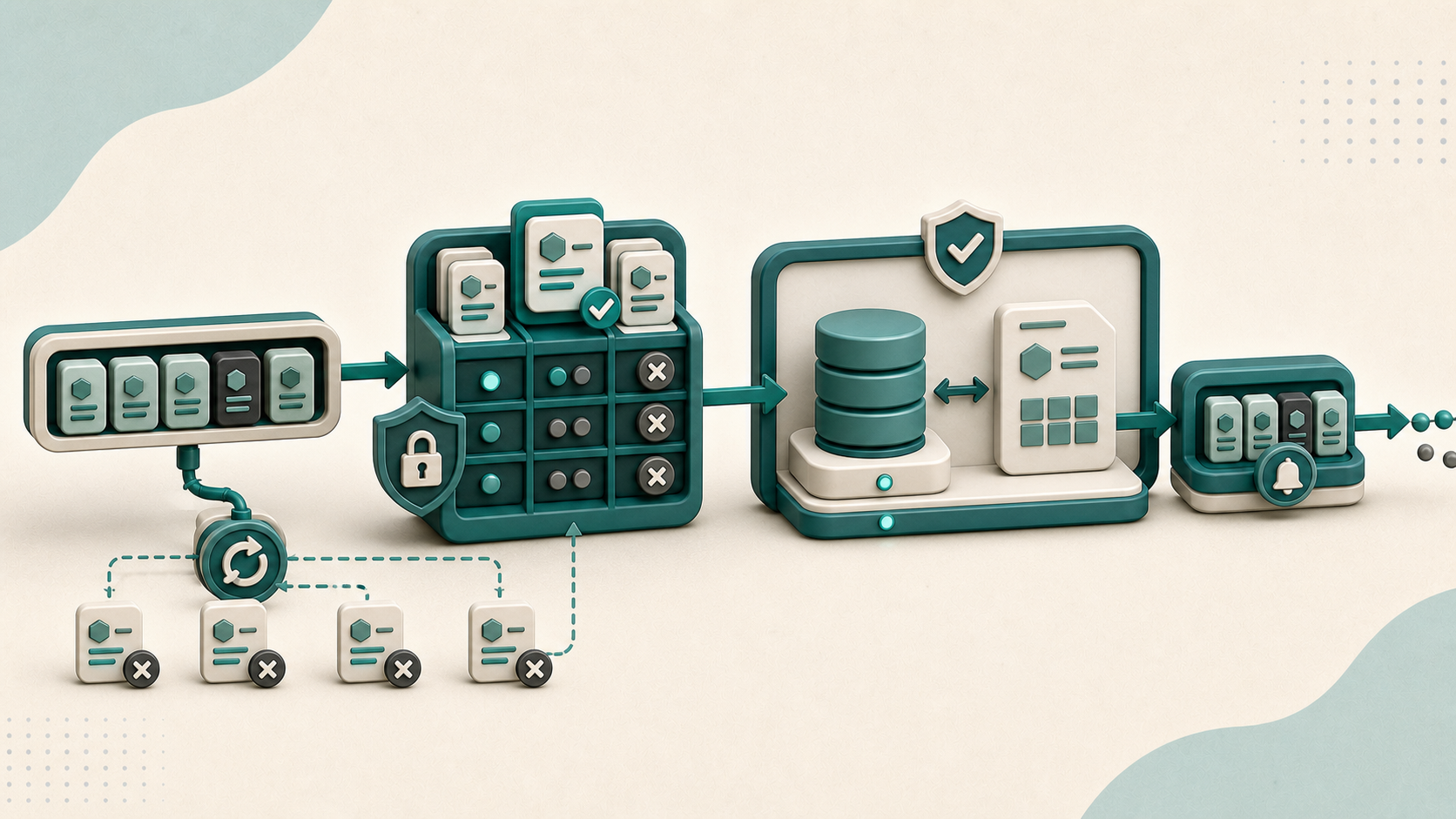
L’article précédent sur le Transactional Outbox a posé une garantie claire : tout événement écrit en base finira par être publié. Cette garantie est volontairement at-least-once. Un consommateur peut recevoir le même événement deux fois, trois fois, ou plus si le réseau se comporte mal. Le pattern Outbox ne promet jamais l’unicité. La conséquence est immédiate : si le consommateur fait deux fois l’effet du message, il facture deux fois, envoie deux emails, débite deux fois le stock. La cohérence garantie côté producteur s’effondre côté lecteur. ...
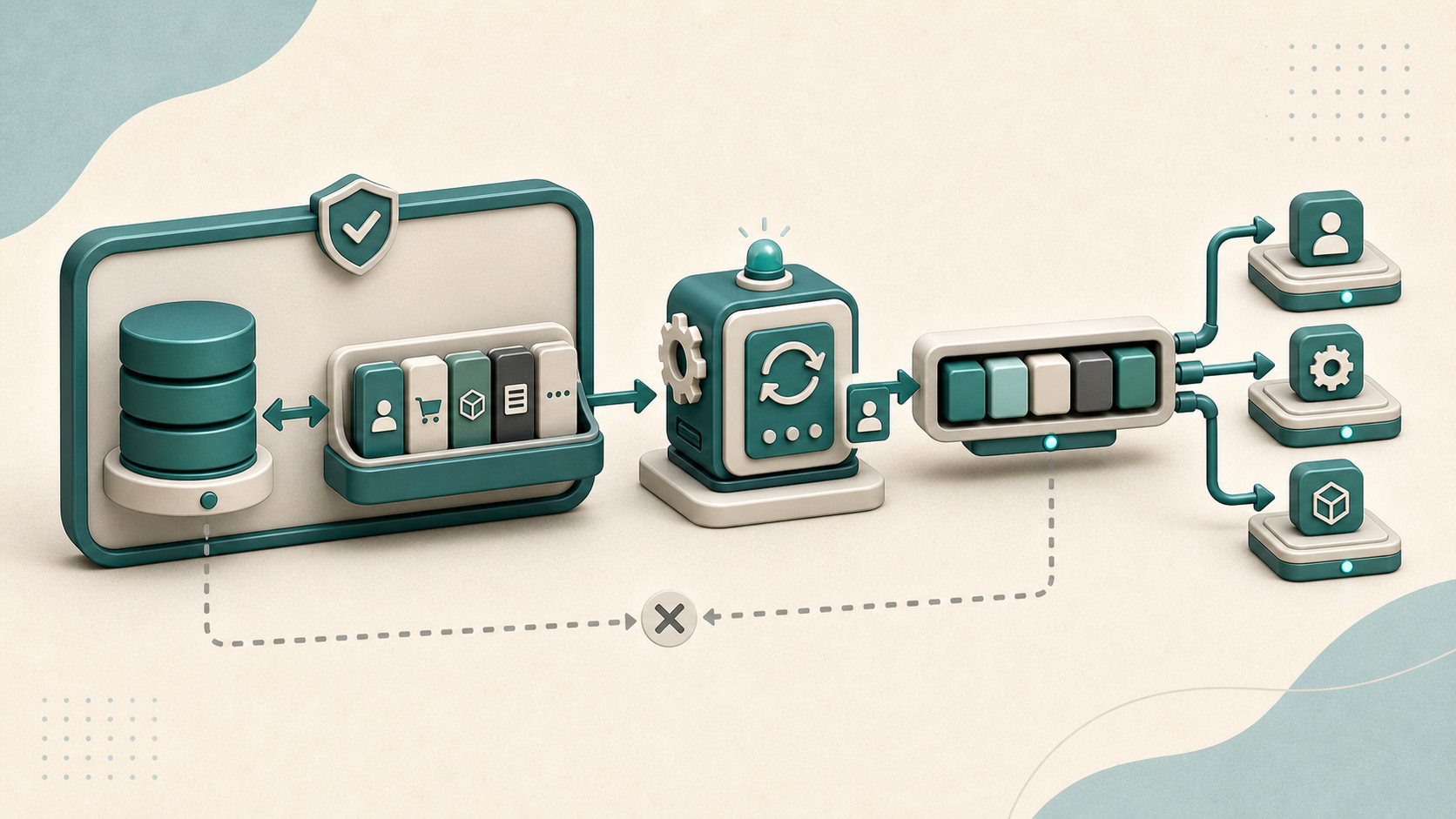
Quand un service modifie sa base et veut prévenir le reste du système d’envoyer un événement à Kafka, RabbitMQ ou SQS, le code naïf ressemble à ça : on écrit en base, puis on publie. Si la publication échoue après la commit, l’événement est perdu. Si la publication réussit mais que la commit échoue, l’événement parle d’un état qui n’existe pas. Ces deux cas sont la définition du dual-write problem. ...
Une opération métier qui touche plusieurs services pose un problème que SQL résout depuis cinquante ans à l’intérieur d’une base unique : que faire quand une étape réussit et que la suivante échoue ? Tant que tout vit dans la même base, BEGIN ... ROLLBACK suffit. Dès qu’on appelle un service externe, une API tierce ou une autre base, ce filet de sécurité disparaît. Le pattern Saga répond à cette question. Plutôt que de tenter une transaction ACID impossible, il découpe l’opération en étapes locales, chacune accompagnée d’une transaction compensatrice qui sait défaire son effet. Si l’étape 4 échoue, on rejoue en sens inverse les compensations des étapes 1, 2 et 3. ...

itertools est un module de la bibliothèque standard qui expose des briques d’itération combinables. Son intérêt n’est pas de remplacer une boucle for par une fonction au nom obscur, mais de manipuler des flux de données sans jamais les charger entièrement en mémoire. Chaque fonction retourne un itérateur paresseux : rien n’est calculé tant qu’on ne consomme pas le résultat. C’est ce qui permet de chaîner des transformations sur des millions d’éléments avec une empreinte mémoire constante. ...

Un test qui doit isoler une fonction de ses dépendances finit souvent par empiler les patch(). Trois dépendances, trois with imbriqués. Cinq dépendances, une pyramide qui pousse le code utile à dix niveaux d’indentation. Le test devient illisible alors que son intention est simple : vérifier un seul comportement à une frontière précise. contextlib.ExitStack résout exactement ce problème. C’est un gestionnaire de contexte qui en agrège un nombre quelconque d’autres, et les ferme tous proprement à la sortie. Voici comment je m’en sers pour garder un test centré sur sa frontière, avec un cas concret sur l’authentification. ...

Consommer une API externe paraît anodin au premier abord. On fait un requests.get, on récupère un dictionnaire, et on l’utilise tel quel dans le reste du code. Le problème commence quand cette même structure JSON se retrouve disséminée dans dix fichiers, et que l’API change un nom de champ ou passe price de float à string. La correction devient une chasse au trésor. La couche anti-corruption (Anti-Corruption Layer, ou ACL) répond à ce problème. Issue du Domain-Driven Design, elle agit comme un traducteur entre un système externe et votre logique métier. Un seul point de contact, un seul endroit à modifier quand l’API change. ...

Les permissions dans Django REST Framework fonctionnent, mais elles montrent leurs limites dès que les règles d’accès deviennent un peu complexes. Plusieurs rôles, des objets appartenant à un utilisateur, des actions custom sur un ViewSet : on se retrouve rapidement avec des classes has_permission et has_object_permission qui mélangent des vérifications hétérogènes, difficiles à lire et encore plus difficiles à tester. rest_access_policy (paquet djangorestframework-access-policy) propose une autre approche : déclarer les règles d’accès sous forme de statements, à la manière des politiques IAM d’AWS. Le résultat est lisible en un coup d’oeil, testable indépendamment du ViewSet, et extensible sans réécrire toute la classe. ...